


Digitalisierung der Postbranche
Naturgemäß sammeln Brief-, Paket- und Logistikunternehmen viele Daten, damit ihr operatives Geschäft reibungslos läuft. Den größten Teil des Big-Data-Kuchens macht dabei im Zustell- und Logistikbereich die Sendungsverfolgung („Track and trace“) aus. Ebenso fallen dem Postdienstleister ERP-Daten an, z. B. einzelne Mengendaten, Routen, Personalinformationen, Standortdaten, Fuhrpark- und Fahrzeugdaten, Kundendaten zu Verkaufserlösen, Abholdaten, Briefkastendaten, Beschwerden und Rückmeldungen sowie schlussendlich auf höchster Ebene die Finanz- und Controlling-Daten.
Bisher wurden diese Daten erhoben, um bestimmte Prozesse zu unterstützen oder zu automatisieren und somit die Effizienz zu verbessern. Das funktioniert gut für die Zwecke, für die es ursprünglich gemacht wurde. Aber in den meisten Fällen sind die Daten nicht so aufbereitet, um damit weitere, umfangreichere Analysen durchführen zu können. Mit diesem Manko müssen sich viele Unternehmen heute auseinandersetzen, wenn sie sich im verschärfenden Wettbewerb der global agierenden e-Commerce- und Logistikunternehmen behaupten wollen. Nur so werden sie die Customer Experience und die Qualität ihrer Services systematisch verbessern sowie innovative Produkte und Dienstleistungen entwickeln.
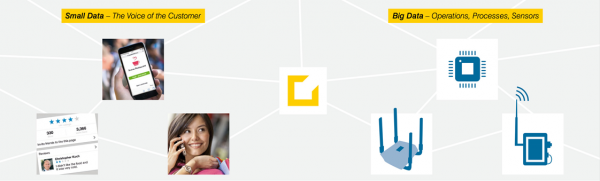
Erst wenn Kundenfeedback (Small Data) und Prozessdaten des Unternehmens (Big Data) miteinander kombiniert werden, ergibt sich für das Management ein vollständiges Bild – die beste Grundlage für strategische Entscheidungen und Innovation.
Innovative, datengetriebene Unternehmen wie Amazon, Alibaba oder Lazada machen Kundendaten und Kundenerlebnisse zum Schlüsselfaktor. Moderne, datengetriebene Unternehmen denken Prozesse immer rückwärts, das heißt vom Kunden aus. Daten, die während der Customer Journey erfasst werden, unterstützen diese Vorgehensweise. Jede Datenquelle und jeder Erfassungsprozess haben also einen klaren Zweck: Die Daten und Maßnahmen müssen stets dazu beitragen, die Servicequalität und das Kundenerlebnis zu optimieren.
Diese Arbeitsweise bzw. das Customer Experience Management hilft Unternehmen, für ihre Kunden einen Mehrwert zu schaffen und diese auf ihrer Plattform zu halten. Beispielsweise erschließt Amazon jede potenzielle Datenquelle, um die bereits vorhandenen Informationen damit anzureichern. Exemplarisch seien die Sendungsverfolgungsdaten genannt, die von allen Logistikpartnern bereitgestellt und für den Kunden in das Portal integriert werden müssen.

Kunden erwarten, dass sie ihre Sendung immer und überall nachverfolgen können. Aber das allein macht aus Kunden noch keine Fans, die ein Unternehmen weiterempfehlen – das Ziel jedes Customer Experience Managements (CEM). So müssen Postdienstleister beispielsweise auch eine Anwendung bereitstellen, die die Sendungsverfolgung ermöglicht, benutzerfreundlich sein (Usability).
Traditionelle Logistikunternehmen haben einen etwas anderen Ansatz zur Datennutzung. Fragen, die häufig zuerst auftreten: Wie dürfen wir diese Daten verwenden? Wie erklären wir das unserer IT-Abteilung?
Diese Herangehensweise ist natürlich das schnelle Ende jeder datengetriebenen Initiative. Wie also mit dieser Situation umzugehen?
Dürfen wir diese Daten nutzen? Ja, aber …
Bei der Digitalisierung der Postbranche sind Datenschutz und Datenschutzbestimmungen natürlich in jedem Fall einzuhalten. Es gibt trotzdem Möglichkeiten, die Daten für weiterführende Analysen zu nutzen, um letztendlich das Kundenerlebnis zu verbessern. Zunächst einmal können die Daten anonymisiert werden, so dass es weiterhin möglich ist, Daten auf einer detaillierten Ebene zu verwenden. Darüber hinaus können die erhobenen Werte auf einer aggregierten Ebene gespeichert werden. Das reicht in der Regel für Analysen aus und und erleichtert zusätzlich die Verarbeitung.
Weiterhin können Postdienstleister Daten, die auf bestimmte Standorte, Branchen oder Abteilungen heruntergebrochen werden, dazu verwenden, um sie den verantwortlichen Mitarbeitern zu präsentieren. Dadurch kann jeder Angestellte seine Leistung und deren Auswirkungen auf das Gesamtergebnis nachvollziehen.
Was wird die IT-Abteilung dazu sagen?
Big-Data-Aufgaben werden oft fälschlicherweise an die IT-Abteilung weitergereicht. Diese kann wahrscheinlich eine Datenbank, Infrastruktur oder Rechenleistung zur Verfügung stellen. Aber sie hat in der Regel nicht die abstrakten Mathematiker, Statistiker, Visualisierer oder Datenexperten, die daraus neue Erkenntnisse gewinnen und Innovationspotentiale sichtbar machen.
Datenanalysen zählen also nicht zu den ursprünglichen Aufgaben der klassischen IT-Abteilung. Deshalb haben datengetriebene Unternehmen, auch außerhalb der Postbranche, in allen Abteilungen Experten verankert, die sich mit Daten sowie Datenanalysen auskennen und auf diese Weise das Geschäft vorantreiben.
Wie soll man anfangen? Six Sigma hat sich bewährt!
Es gibt einige sehr wertvolle datengetriebene Ansätze in der Geschäftswelt, die in vielen Unternehmen existieren, auch in traditionellen. Diese Ansätze sind viel älter als Big Data und der ganze Wirbel, der darum gemacht wird. Eine Variante ist Six Sigma, das in vielen Fertigungsindustrien eingesetzt wird. Es hält nützliche Werkzeuge bereit, wie mit Daten umgegangen werden kann, immer aus der Perspektive der Kunden. Korrekt und mit dem richtigen Team umgesetzt, kann Six Sigma dabei helfen, die Daten des Unternehmens besser zu nutzen und neue Lösungen zu finden, um das eigene Geschäftsmodell an Marktveränderungen anzupassen.
Gute Nachricht für engagierte Unternehmen bei der Digitalisierung der Postbranche: Die nächste Generation hat eine unbefangenere Einstellung zu Daten. Deshalb bringen Unternehmen die Dinge am einfachsten zum Laufen, indem sie ein paar junge, unvoreingenommene, datenversierte Mitarbeiter einstellen und sie einfach ihren Job machen lassen!
Noch Fragen offen? Hier erfahren Sie mehr zum Thema Digitalisierung und Automatisierung in der Postbranche!
Webinar zum Thema Zu unseren Lösungen
![]()
Fallstudien, Branchen-News, Events und viel mehr – all das finden Sie auf unserem LinkedIn Kanal!
